
Metrics, Alarms, and Alerts
Metrics are the data that provides insights into the performance and health of your system. The metrics emitted by managed services give you a window into your utilization of the provided resources. You can also emit custom metrics from your Lambda functions (see Chapter 6 for information on using the open source Lambda Powertools toolkit for custom metrics). In AWS, all native and custom metrics are sent to CloudWatch. These metrics can then be forwarded to other AWS services or third parties for further analysis and aggregation.
An alarm is a combination of a metric and a threshold. If the metric breaches a certain threshold, the alarm will be triggered. For example, you could configure an alarm to trigger if the number of 400 errors returned by your API exceeded 27% of the total number of requests in the last 5 minutes (see Figure 8-1).
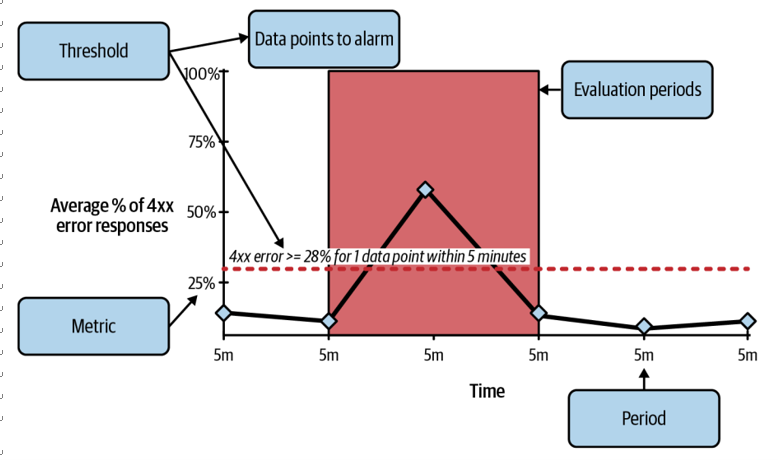
Figure 8-1. Anatomy of a CloudWatch alarm
Alerts are the actions performed when an alarm is triggered, such as sending a mes‐ sage to your team’s chat channel or creating a bug report in your ticketing platform (see Figure 8-2). Alert configuration is important—after all, if an alarm sounds but nothing is listening, will it be heard? That said, you should keep in mind that not all alarms need to trigger an alert. Alarms can be used in operational dashboards to indicate potential issues for delayed investigation or even in retrospective analysis of historical patterns.
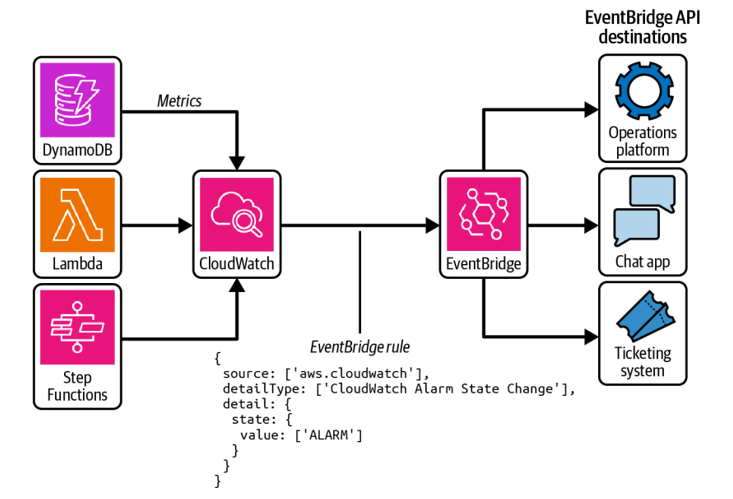
Figure 8-2. Alerting pipeline
Combining metrics, alarms, and alerts is key to surfacing issues with your serverless application. If you don’t make use of these tools, your users are going to be the first to find out about problems and will be your main source of bug reporting. However, without a structured approach, alert noise can quickly overwhelm your team. Alarms that are too granular or sensitive will fast become dismissable and contribute to overall distrust of your alerting pipeline. It can become impossible to filter the signal from the noise. Alerts should be used sparingly and only for the aspects of your application’s performance that are absolutely critical to your users and business.
A useful alert has the following properties:
Obvious
The impact on the user experience or critical path should be clear.
Actionable
The alert should be associated with a clear action.
Singular
The alert should be unique. Problems shouldn’t be reflected by multiple triggers of the same alarm. You should receive one alert per distinct issue.
Refer to Google’s Site Reliability Engineering book for more information about the desired attributes of an alert.
Later in this section you will be introduced to the concept of service level objectives and capability alerting, which can help you to decide on the metrics and indicators to use for your alarms and keep noise to a minimum.