
Capability Alerting
Take a moment to imagine the following scenario. The day has finally arrived: you have spent weeks designing and building your beautiful serverless architecture, and now it is time to release it to your expectant users. But you recognize that a diligent serverless engineer never operates an application in production without alerts. How else will you know if your users are seeing errors without them telling you? You take a step back and look at all the components in your system: an API Gateway REST API, multiple microservices consisting of Lambda functions and Step Functions workflows, a DynamoDB table to store application state, and several EventBridge rules connecting all the services together. You wonder which metrics are important and when you should trigger alarms. Which parts do you need to know are broken, and when? You select the obvious, key parts: API 5xx errors, Lambda function errors, DynamoDB write throttles, and EventBridge delivery failures.
What follows is an all-too-common experience. With a large set of alarms for very specific metrics and thresholds, your engineers will quickly become overwhelmed by a barrage of alerts, many of which will be false positives (the threshold was too low or the selected metric was incorrect) or deemed acceptable (“this usually fails”) or expected (“that’s a known error”).
While this is a perfectly acceptable start to introducing alerting to your observability practice (and is much better than having no alerts at all), you should be aware of an alternative approach. Capability-based alerting involves assessing the overall health of a critical component or service in your system. Let’s say one of the critical capabilities of your system is to generate a PDF and store it in S3. In this instance, you would combine metrics across the components in this workflow to form an overall idea of the health of this service and establish a baseline of acceptable performance in a CloudWatch composite alarm. You would then receive an alert when this threshold was breached and would know the performance of this capability had degraded enough to warrant your immediate attention. Without capability-based alerting, you would have instead received multiple alerts tied to specific resource metrics, which would have created a lot of noise and been ineffective at pinpointing the area on which to focus your initial debugging efforts.
Ideally, you want to receive alerts based on the health of your system’s capabilities (see Figure 8-4). Monitoring the health of your entire system is far too broad to provide actionable insights, while monitoring the health of your system’s components is much too granular to give any useful indications.
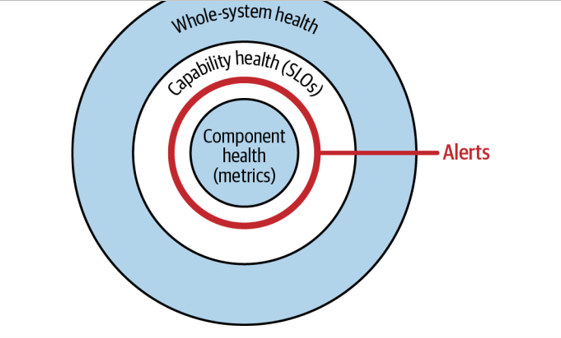
Figure 8-4. The layers of alerting
Service level objectives can also be used to answer the question “How will the quality of this code be measured?” from “Upholding Standards with a Definition of Done” on page 328.